The Dataset
For this Lab, we will use a synthetic dataset, thanks to Ribbon Communications.
The data was generated by call test generators, and is not customer or
sensitive data.
Inspecting the data
The example below is a typical CDR. The STOP CDR shown below is generated after a call has been terminated.
As you can see, there are a lot of values here. Most of them are not relevant for fraud identification or prevention.

based on our use case, the following pieces of information are most relevant to detecting fraud.
- Call duration
- Calling number (
A-number) - Called number (
B-number) - Start time of the call
- Accounting ID
You can use this reference to help identify those fields in a CDR.
In the following figure you can see an example of decoded CDR data with fields
relevant to our analysis highlighted.
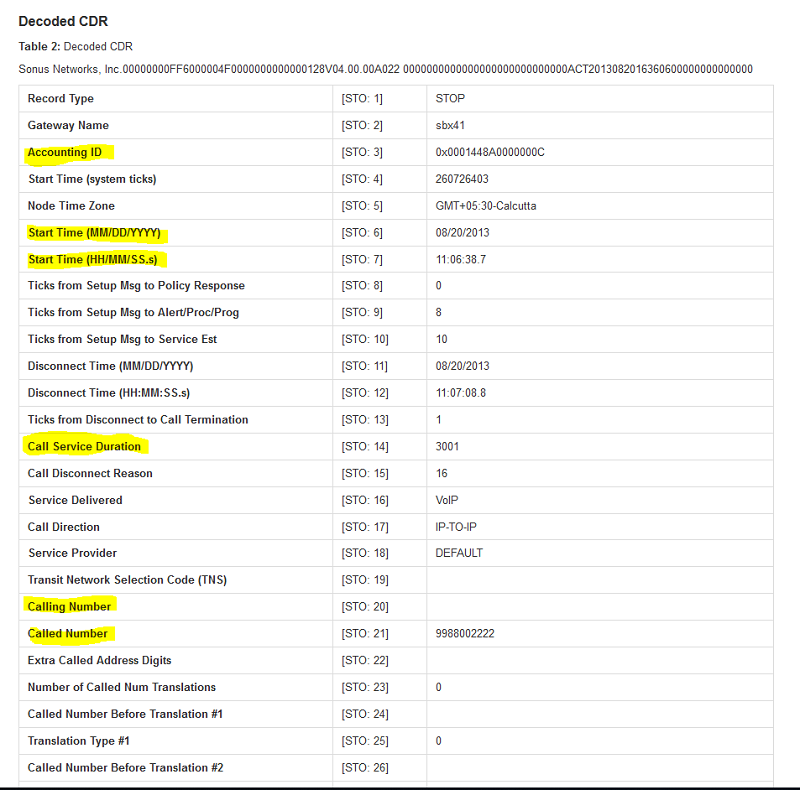
We identified the columns that we need out of 235 columns in the CDR.
By inspecting the raw sample data, we quickly understand that it’s missing a header.
To make life easier, we converted the raw CSV data, added the column names, and converted to Parquet.